
The QCPA framework uses both chromatic (colour) and achromatic (luminance/brightness) differences to analyse images. The colour component is provided by “cone catch” images, where each receptor has its own channel, and these are compared in the receptor noise limited colour space. Luminance must also be included, although it may not always be apparent how exactly a given animal perceives luminance.
The QCPA framework requires input images where the first slices in the stack must be the chromatic channels, with a final luminance slice in the stack. Here are examples of input image stacks for tetra-, tri- and di-chromatic modelling:

If the cone-catch model doesn’t create a final luminance channel automatically (e.g. the “double” cones in birds), you will need to add your own. This will vary between visual system. For humans (e.g. either using CIE XYZ, or LMS cone catch images) it is standard to take the average of the LWS (or CIE X) and MWS (or CIE Y) channels for the luminance channel. For other species it will often just be the most abundant cone channel on its own (e.g. the MW channel for a dichromatic mammal), or the average of all receptor channels. If in doubt, or there is no evidence to support any specific method then consider repeating the analysis using different strategies. There is a tool in the toolbox which lets you create this luminance channel based on any of these configurations:
Input Requirements & Running the tool
This tool requires a cone-catch image, then simply run:
plugins > micaToolbox > Image Transform > Create Luminance Channel
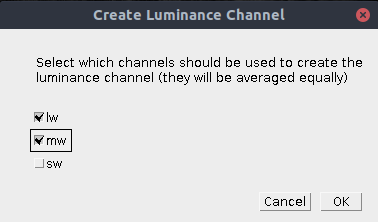
This tool adds a final luminance channel at the end of the cone-catch image stack, based on an equal average of all the selected channels.